数学基础#
散度定理#
函数 F=(P,Q,V)
∮∂VF⋅dS=∫V∇⋅FdV
∮∂VPdydz+Qdxdz+Vdxdy=∫V(∂x∂P+∂y∂Q+∂z∂V)dV
梯度与拉普拉斯算子#
为了描述空间中温度的变化,引入了两个重要的数学算子:
温度差(梯度 ∇u):
∇u=(∂x∂u,∂y∂u,∂z∂u)
梯度代表了温度变化最剧烈的方向。热量总是沿着梯度的反方向(从高温到低温)流动的。
拉普拉斯算子 (Δu 或 ∇2u):Δu=∇⋅(∇u),即梯度的散度。它描述了空间某点温度的“不均匀性”或“平均差”。
热传播方程:#
通过散度定理,我们可以把曲面上的热通量转化成体积内的变化:
- 左侧(流出量):利用散度定理,将闭合曲面上的温度梯度积分转化为体积积分:
∮∂V∇u⋅dS=∫V∇⋅∇udV=∫VΔudV
- 右侧(变化量):根据物理定律,内部热量的变化与温度随时间的变化率 ∂t∂u 相关:
λ∫V∂t∂udV
- 最终方程:由于上述等式对任意体积 V 都成立,消去积分号得到热传播方程:
Δu(x,t)=λ∂t∂u(x,t)
图上的微分算子#
我们将三维空间中的函数简化为定义在图 G=(V,E) 上的函数。
- V (Vertices):顶点,相当于空间中的采样点。
- E (Edges):边,代表点与点之间的邻接关系。
- fi:定义在顶点 vi 上的标量值(例如该点的温度、高度或颜色)。
图上的梯度
在连续空间,梯度描述函数值的变化。在图上,梯度定义在边 eij 上:
∇G∣eij=fi−fj
图上的拉普拉斯算子#
通过“热传播”的视角,我们可以推导出顶点 vi 处的离散拉普拉斯算子:
ΔG∣vi=Ni1j∈Neighi∑(fj−fi)
- Neighi:顶点 vi 的所有邻居节点。
- Ni:邻居节点的数量(度数)。
- 直观理解:它计算的是该点值与周围邻居平均值的差。如果 ΔG>0,说明该点比周围“冷”;如果 ΔG<0,说明该点比周围“热”。
拉普拉斯平滑#
平滑一个 3D 模型(网格)的过程,在数学上等同于让模型上的点坐标按照**扩散方程(Diffusion Equation)**进行演化。
- 方程:∂t∂f(vi,t)=λΔf(vi,t)
- 离散近似:∂t∂f(t)≈hf(t+h)−f(t)
- 直观理解:网格上的每一个点 vi 都会向其邻居的平均位置移动。随着时间 t 的推移,尖锐的噪点会被“抹平”,模型变得圆润。
为了在计算机上实现这个方程,我们需要将连续的时间微分 ∂t∂f 离散化。
求解 (I−τL)fk=fk−1 (求解 Ax=b) 的方法:
Cholesky 分解 (LLT)
当矩阵 A 是对称正定的时,LU 分解可以进一步简化为 LLT。
- 公式:A=LLT
- 求解步骤:
- 先解 Ly=b(前向替换)。
- 再解 LTx=y(后向替换)。
- 技巧:
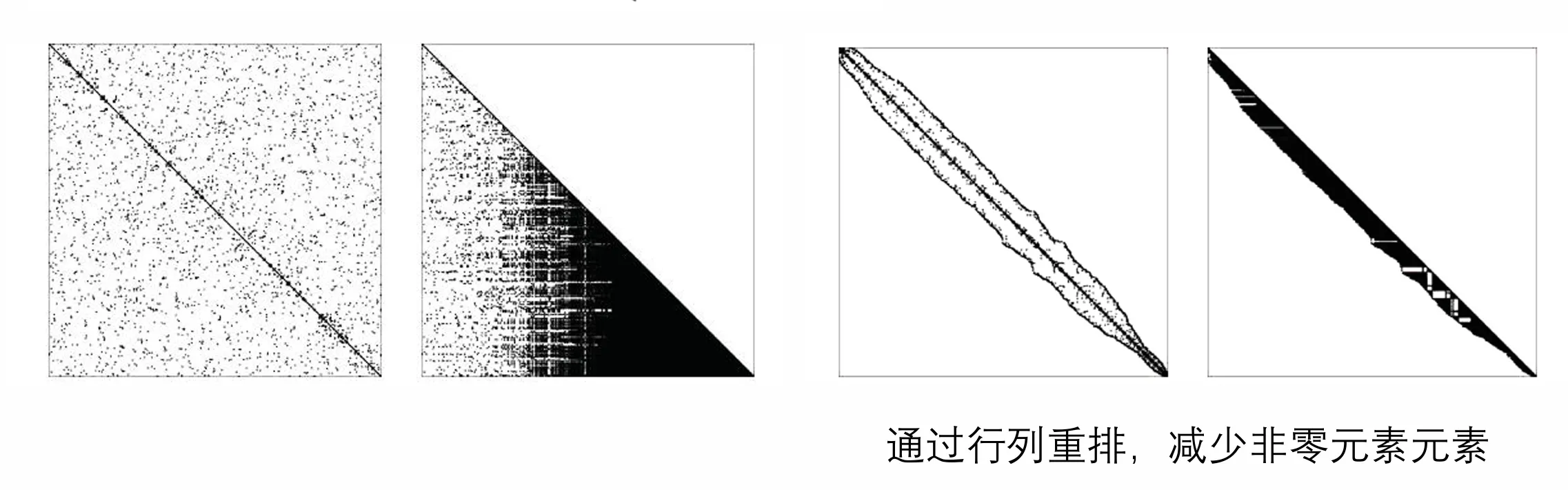
对于这里的矩阵,他极大概率是稀疏的,直接分解对内存的开销过大。使用重排的方法把非零元集中到对角线附近,可以大大减少分解时产生的非零元。
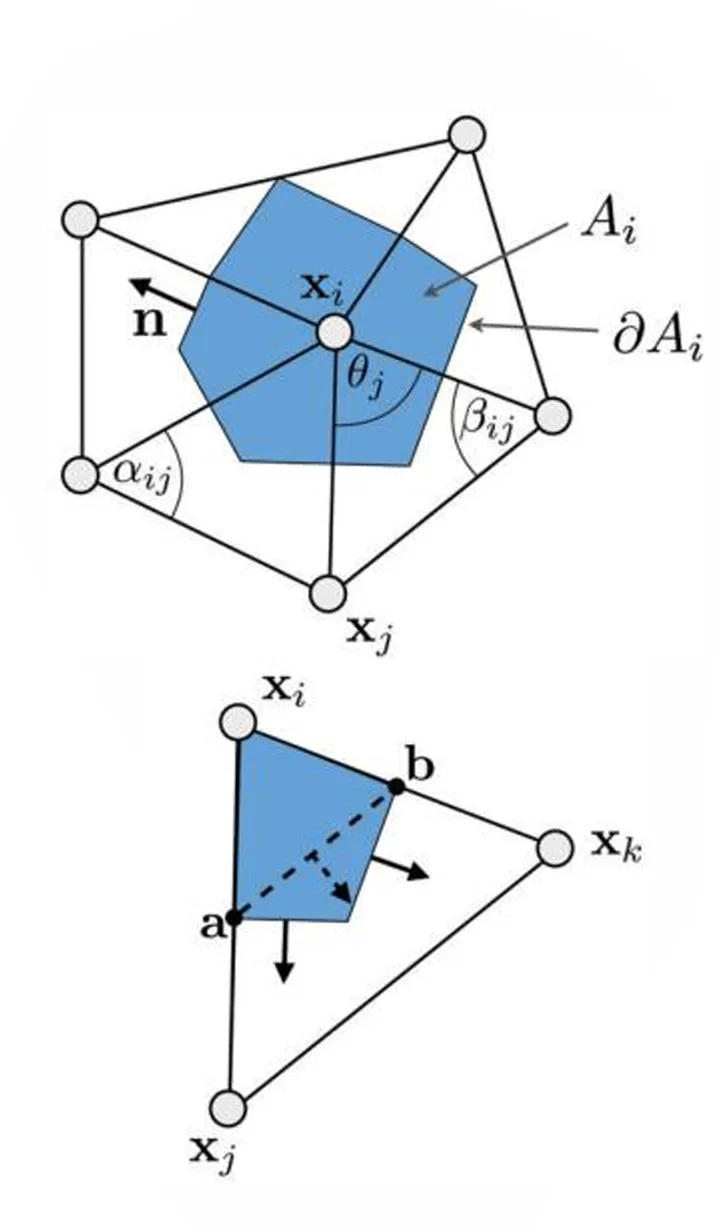
三角形网格#
在网格中,我们只知道顶点 (vi,vj,vk) 上的值 fi,fj,fk。为了计算三角形内部任意点 x 的值,我们需要使用重心坐标插值 (Barycentric Interpolation):
f(x)=Bi(x)fi+Bj(x)fj+Bk(x)fk
-
Bi(x):线性基函数(或者叫插值权重)。它的特点是在顶点 i 处为 1,在其他顶点处为 0,且在三角形内部线性变化。
-
基函数的梯度
因为 Bi(x) 是一个线性函数,它的梯度 ∇Bi(x) 是一个常数向量。
-
几何意义:∇Bi(x) 的方向垂直于对边(即边 ejk),且大小与三角形的面积 AT 成反比。
-
公式表达:∇Bi(x)=2AT(xk−xj)⊥。这里的 ⊥ 表示将向量旋转 90∘(法向方向)。
-
三角形梯度公式
将基函数的梯度代入插值公式,我们得到整个三角形面片上的梯度向量:
∇f(x)=(fj−fi)2AT(xi−xk)⊥+(fk−fi)2AT(xj−xi)⊥
-
三角形网格内的拉普拉斯算子
根据上面的梯度公式,我们可以推导出顶点的拉普拉斯算子:
根据散度定理
∫AiΔf(u)dA=∫Aidiv∇f(u)dA=∫∂Ai∇f(u)⋅n(u)ds
其中 Ai 是顶点 vi 周围的对偶区域,n 是边界法向量。
单个三角形内的通量积分
针对 ∂Ai∩T(即落在某个三角形 T 内的那部分对偶边界)进行计算:
∫∂Ai∩T∇f(u)⋅n(u)ds=∇f(u)⋅(a−b)⊥=21∇f(u)⋅(xj−xk)⊥
代入梯度公式进一步推导得到:
=(fj−fi)4AT(xi−xk)⊥⋅(xj−xk)⊥+(fk−fi)4AT(xj−xi)⊥⋅(xj−xk)⊥
利用向量点积与余切值的几何关系简化为:
=21(cotγk(fj−fi)+cotγj(fk−fi))
离散拉普拉斯算子最终公式 (Discrete Laplacian)
将周围所有邻接三角形的贡献加总,得到顶点 vi 处的余切权重公式:
Δf(vi):=2Ai1vj∈N1(vi)∑(cotαi,j+cotβi,j)(fj−fi)
Ai:顶点 vi 的对偶区域面积(混合面积)。N1(vi):顶点 vi 的一阶邻域(即所有相连的邻居点)。αi,j,βi,j:共享边 (vi,vj) 的两个相邻三角形中,与该边相对的两个内角。(fj−fi):相邻顶点间的函数值差。
由此求得的拉普拉斯矩阵,也可以用于拉普拉斯平滑的计算。
双边网格去噪#
核心算法流程:
v^=v+n⋅(∑wcws∑wcwsh)
法向量双边滤波#
第一步:法向量滤波。先不管顶点坐标,只对面片的法向量进行双边滤波。
处理的对象变成了法向量 n:
nik+1=Ki1j∑Wσs(…)⋅Wσr(∥nik−njk∥)⋅njk
- 优点:如果两个相邻面片分别属于两个不同的平面(如立方体的顶面和侧面),它们的法向量差别很大。值域权重 Wσr 会识别出这种巨大差异并停止平滑,从而保持尖锐特征(Sharp Features)。
第二步:更新顶点位置。根据平滑后的法向量,反过来调整顶点坐标,使三角形面片重新对齐这些法向量。
e1(X)=k∈F∑(i,j)∈∂Fk∑(nk′⋅(xi−xj))2
- 梯度下降法求解
利用梯度下降法不断迭代顶点位置,直到误差最小:
xi′=xi+λj∈NV(i)∑(i,j)∈∂Fk∑nk′(nk′⋅(xj−xi))
稀疏优化#
- 目标:使图像或网格的梯度尽可能稀疏。下面先看图像。
- 数学表达:minc∣c−c∗∣2+λ∣∇c∣0
- ∣c−c∗∣2:数据项,保证平滑后的结果不能偏离原图太远。
- ∣∇c∣0:稀疏项(L0 范数),统计梯度不为 0 的像素点个数。越小代表平面越多,边缘越锐利。
算法实现:交替方向乘子法 (ADMM 思想)
由于 L0 范数是不可导的(NP-hard 问题),我们可以通过引入辅助变量 δ 来求解:
- 拆解方程:将原问题转化为 minc,δ∣c−c∗∣2+β∣∇c−δ∣2+λ∣δ∣0。
- 固定 c,更新 δ (Local Step):这是一个硬阈值操作。如果梯度不够大,直接砍成 0;如果够大,保留原样。
- 固定 δ,更新 c (Global Step):这是一个全局优化问题,通常转化为解线性方程组。
将此技术应用到 3D 网格时,面临一个问题:如何定义网格上的“梯度”或“拉普拉斯”?
直接用“点的拉普拉斯”会导致模型像被抽真空一样严重收缩,且棱角依然不清晰。
-
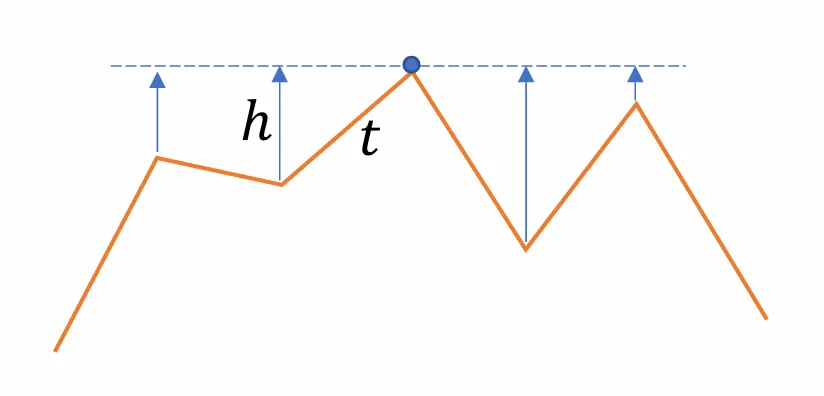
边上的拉普拉斯算子 D(e):
2013 年的研究(如 L0 Mesh Smoothing)将关注点从点移到了边。
算子定义在共享边 e 的两个三角形上,涉及四个顶点:
- p1,p3:共享边 e 的两个端点。
- p2,p4:分别属于两个三角形的相对顶点。
与之对应的有四个关键角度:θ2,3,1,θ1,3,4,θ3,1,2,θ4,1,3(即每个三角形内靠近共享边端点的内角)。
边上的拉普拉斯算子 D(e) 是一个线性算子,将四个顶点的坐标映射为一个标量值(代表该边的“翻折”或“非平坦”程度):
D(e)=−cot(θ2,3,1)−cot(θ1,3,4)cot(θ2,3,1)+cot(θ3,1,2)−cot(θ3,1,2)−cot(θ4,1,3)cot(θ1,3,4)+cot(θ4,1,3)Tp1p2p3p4
在 2013 年的论文中,这个算子被放入 L0 范数中:
pmin∣p−p∗∣2+λ∣D(p)∣0
基于机器学习的网格去噪#